Querying from Microsoft Fabric
This guide offers a short tutorial on how to query Apache Iceberg and Apache Hudi tables in Microsoft Fabric utilizing
the translation capabilities of Apache XTable™ (Incubating). This tutorial is intended solely for demonstration and to verify the
compatibility of Apache XTable™ (Incubating) output with Fabric. The tutorial leverages the currently1 available features in Fabric, like
Shortcuts.
What is Microsoft Fabric
Microsoft Fabric is a unified data analytics platform for data analytics. It offers a wide range of capabilities including data engineering, data science, real-time analytics, and business intelligence. At its core is the data lake, OneLake, which provides tabular data stored in Delta Parquet format, allowing one copy of the data to be used in all Fabric analytical services like T-SQL, Spark, and Power BI. OneLake is designed to do away with the need for data duplication and eliminates the necessity for data migration or transfers. Whether it's a data engineer adding data to a table using Spark or a SQL developer analyzing data with T-SQL in a data warehouse, both can access and work on the same data copy stored in OneLake. Additionally, OneLake enables integration of existing storage accounts via its 'Shortcut' feature, which acts as a link to data in other file systems.
Tutorial
The objective of the following tutorial is to translate an Iceberg or Hudi table in ADLS storage account into Delta Lake format using Apache XTable™ (Incubating). After translation, this table will be accessible for querying from various Fabric engines, including T-SQL, Spark, and Power BI.
Pre-requisites
- An active Microsoft Fabric Workspace.
- A storage account with a container in Azure Data Lake Storage Gen2 (ADLS).
Step 1. Create a source table in ADLS
This step creates a source table in Iceberg or Hudi format in the ADLS storage account. The primary actions to be
taken to create a table people in Iceberg or Hudi format are documented in
Creating your first interoperable table - Create Dataset tutorial section. However, instead of creating the
people table locally, configure local_base_path to point to the ADLS storage account.
Assuming the container name is mycontainer and the storage account name is mystorageaccount, the local_base_path
should be set to abfs://mycontainer@mystorageaccount.dfs.core.windows.net/.
An example spark configuration for authenticating to ADLS storage account is as follows:
spark.hadoop.fs.azure.account.auth.type=OAuth
spark.hadoop.fs.azure.account.oauth.provider.type=org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider
spark.hadoop.fs.azure.account.oauth2.client.endpoint=https://login.microsoftonline.com/<tenant-id>/oauth2/token
spark.hadoop.fs.azure.account.oauth2.client.id=<client-id>
spark.hadoop.fs.azure.account.oauth2.client.secret=<client-secret>
Step 2. Translate source table to Delta Lake format using Apache XTable™ (Incubating)™
This step translates the table people originally in Iceberg or Hudi format to Delta Lake format using Apache XTable™ (Incubating).
The primary actions for the translation are documented in
Creating your first interoperable table - Running Sync tutorial section.
However, since the table is in ADLS, you need to update datasets path and hadoop configurations.
For e.g. if the source table is in Iceberg format, the configuration file should look like:
sourceFormat: ICEBERG
targetFormats:
- DELTA
datasets:
-
tableBasePath: abfs://mycontainer@mystorageaccount.dfs.core.windows.net/default/people
tableDataPath: abfs://mycontainer@mystorageaccount.dfs.core.windows.net/default/people/data
tableName: people
# In the configuration above `default` refers to the default spark database.
An example hadoop configuration for authenticating to ADLS storage account is as follows:
<configuration>
<property>
<name>fs.azure.account.auth.type</name>
<value>OAuth</value>
</property>
<property>
<name>fs.azure.account.oauth.provider.type</name>
<value>org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider</value>
</property>
<property>
<name>fs.azure.account.oauth2.client.endpoint</name>
<value>https://login.microsoftonline.com/[tenant-id]/oauth2/token</value>
</property>
<property>
<name>fs.azure.account.oauth2.client.id</name>
<value>[client-id]</value>
</property>
<property>
<name>fs.azure.account.oauth2.client.secret</name>
<value>[client-secret]</value>
</property>
</configuration>
java -jar xtable-utilities/target/xtable-utilities_2.12-0.2.0-SNAPSHOT-bundled.jar --datasetConfig my_config.yaml --hadoopConfig hadoop.xml
Running the above command will translate the table people in Iceberg or Hudi format to Delta Lake format. To validate
the translation, you can list the directories in the table's data path. For this tutorial, _delta_log directory
should be present in the people table's data path at default/people/data/_delta_log.
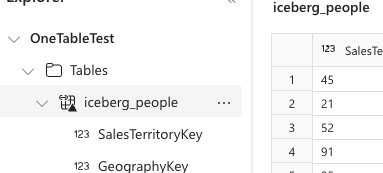
Step 3. Create a Shortcut in Fabric and Analyze
This step creates a shortcut in Fabric to the Delta Lake table created in the previous step. The shortcut is a link to the table's data path in ADLS storage account.
- Navigate to your Fabric Lakehouse and click on the
Tablesand selectNew Shortcut.
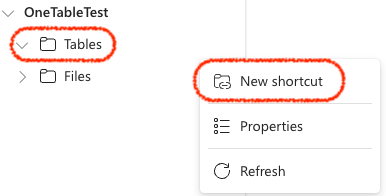
- In the
New Shortcutdialog, selectAzure Delta Lake Storaget Gen2as theExternal Source
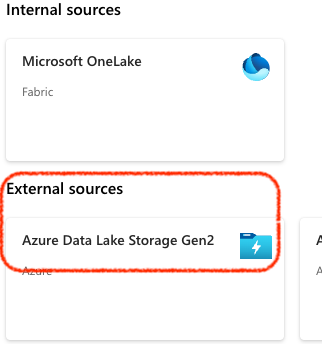
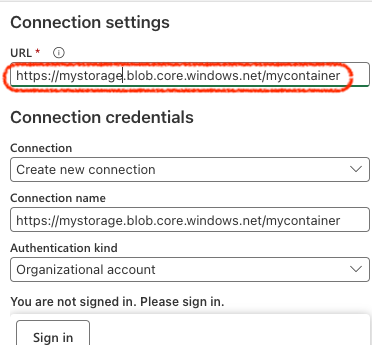
- In the
New Shortcutdialog, enter theConnection settingsand authorize Fabric to access the storage account.
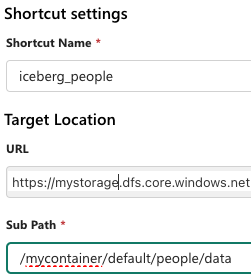
- In the
New Shortcutdialog, enter theShortcut settingsand clickCreate.
- The shortcut is now created and the table is available for querying from Fabric.
Footnotes
-
Updated on 2023-11-16 ↩